

NVIDIA STUDIO由于各种生产力工具软件(如视频编辑、3、D建模渲染等。)开始支持NVIDIA自从显卡硬件加速以来,N卡就成为了设计师用户装机或者购买整机的首选,而NVIDIA最终为设计师用户推出了完整的产品NVIDIA STUDIO解决方案(包括NVIDIA显卡、STUDIO驱动程序和各种黑科技功能)。第一代支持光追Turing架构出现,NVIDIA STUDIO强大让设计师用户惊叹,支持第二代光追加速Ampere结构,更是让步NVIDIA STUDIO里程碑级提高了功能和效率。
不仅玩游戏强,NVIDIA Ampere结构生产力更锐利

与上一代架构相比,Ampere的SM单元、RT Core和TENSOR Core升级

我们熟悉的RTX 采用30系列显卡NVIDIA Ampere架构,采用三星8nm与上代架构相比,先进的工艺大大提高了晶体管的数量和执行效率。从数据上看,Ampere架构的SM单位提供数量翻倍的单位FP32单元,每个时钟周期可实现128bit FMA浮点运算;全新的 L1缓存/材料系统提供双倍L总容量增加33%的缓存带宽和缓存分区尺寸;配备新的加速核心,第二代包括两倍三角形相交率RT Core具有两倍稀疏矩阵计算能力的第三代TENSOR Core。这些升级让Ampere架构的SM单元FP32最高计算能力提高了173%左右,RT Core最高计算能力提高了71%左右,TENSOR Core最高计算能力提高了约167%,这些都是NVIDIA Ampere在各种生产力软件中,架构强大的加速能力奠定了硬件基础。

以RTX 以3080为例,得益于工艺升级,芯片规模与上一代对位产品相比大幅提升
在实际应用中,Ampere架构升级带来了什么改进?第一代,第二代RT Core在计算光跟踪时,可以同时计算三角形交叉和时间插值,从而实现光跟踪特效的动态模糊效果。在这个计算过程中,它相当于提供了最快射线穿越计算性能的8倍,我相信它通常需要完成3D设计师用户很清楚这意味着这将带来多高的效率提升。
其次,虽说RTX 每个30系列显卡SM单元的TENSOR Core但由于数量的减少TENSOR Core升级到第三代,最终效率大大提高。举个例子,RTX 2080 SUPER每个SM一个时钟周期可以完成512次FP16浮点操作,RTX 3080只使用第三代的一半数量TENSOR Core512次(密集矩阵)/1024次(稀疏矩阵)单时钟周期即可完成FP16浮点操作,这样看,第三代TENSOR Core与上代相比,效率提高了一倍左右。
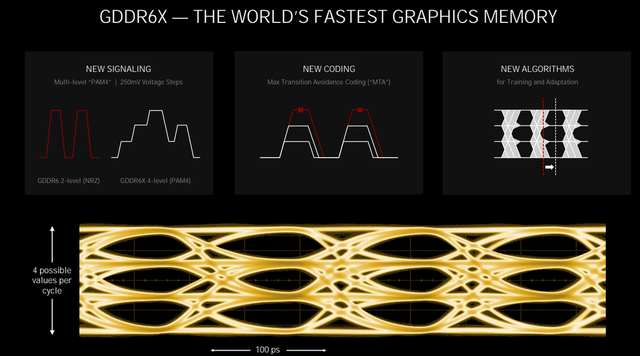
RTX 3090/RTX 3080采用GDDR6X显存,速率为GDDR6的两倍
此外,Ampere架构的RTX 3090/3080显卡还有一个巨大的升级,即使用NVIDIA与美光合作开发GDDR6X显存。由于GDDR6X显存采用了PAM4信号编码,即每个周期使用4个电平信号进行数据传输,与效率相比GDDR6的两个电平信号显著增加,带来了更高的显存数据带宽,在需要大量显存数据交换的专业设计应用中具有很高的实用意义。

RTX 提供30系列显卡HDMI 2.1接口,单数据线输出8K/60Hz HDR视频信号也提供了正确的AV1.加速硬件解码,支持8K/60fps视频实时解码
采用NVIDIA Ampere架构的RTX 提供30系列显卡了对HDMI 2.支持1接口,单数据线8可以实现K/60Hz或者4K/120Hz的HDR画面输出。此外,RTX 30系列也是世界上第一批支持AV1.硬件解码显卡可流畅解码8K/60fps视频也是视频编辑用户非常有价值的特征。

RTX 30系列显卡的高超算力为内容创作提供了强大的动力
在渲染动态模糊画面时,RTX 3080的性能约为RTX 2080 SUPER的5倍
在达芬奇视频剪辑中,RTX 3080的效率甚至超过了RTX 2080 SUPER的两倍
正是因为Ampere基于硬件性能,架构带来了硬件性能的飞跃RTX 30显卡的NVIDIA STUDIO解决方案也大幅升级。根据官方数据,RTX 3080在各种主流渲染器中的加速性能远远超过RTX 2080 SUPER,在LUXMARK和V-Ray甚至超过了RTX 2080 SUPER的两倍。视频剪辑部分,RTX 3080也表现出惊人的性能,DaVinci测试中的成绩远远领先RTX 2080 SUPER,甚至有些项目几乎都达到了RTX 2080 SUPER的2.5倍性能。视频剪辑部分,RTX 3080也表现出惊人的性能,DaVinci测试中的成绩远远领先RTX 2080 SUPER,甚至有些项目几乎都达到了RTX 2080 SUPER的2.5倍性能。总之,设计师用户现在一起开始RTX 30显卡可以大大提高工作效率和工作体验。
当然,除了升级制造工艺、架构和硬件规格外,Ampere架构的RTX 30显卡还为设计师用户提供了大量的黑色技术功能。
新一代黑科技助力!RTX 30显卡专业应用更高效
RTX IO快速载入技术
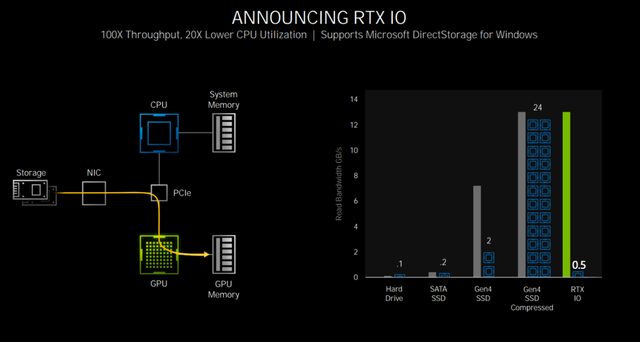
RTX IO压缩数据可以直接读取到显存,CPU占用率降低20倍,载入速度相对于HDD提升百倍
鉴于磁盘数据载入特别占用处理器资源,效率较低,NVIDIA推出了RTX IO通过这项技术,技术可以使GPU处理数据解压,大大降低CPU的占用率。从图中可以看出,在PCIe 4.当固态硬盘达到相同的读取速度时,如果采用传统方法,将占用24个CPU采用核心RTX IO技术之后,只需占用0.5个CPU在实际的创意设计应用中,核心可以体现在加载材料和项目文件时更加流畅。要享受这项技术,软件需要支持微软DirectStorage API,当然也需要RTX 30系列显卡。
NVIDIA OMNIVERSE MACHINIMA
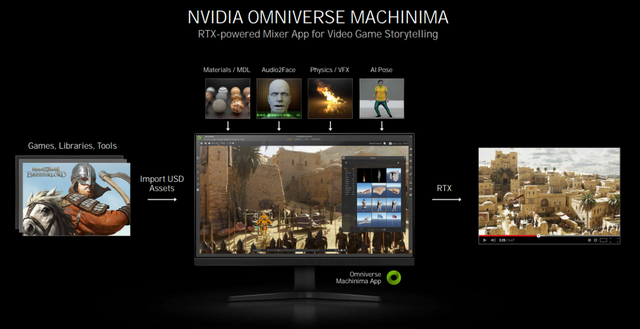
通过NVIDIA OMNIVERSE MACHINIMA用户可以使用游戏素材制作电影级视频
NVIDIA OMNIVERSE MACHINIMA是基于RTX 30系列GPU计算能力强APP,通过现有的游戏素材,设计师用户可以使用它RTX 30显卡AI制作电影级视频的技术。NVIDIA OMNIVERSE MACHINIMA从支持该技术的游戏中获持该技术的游戏中获取材料和工具Audio2Face(声音转表情),增加物理效果,AI采集动作,最后使用RTX光线跟踪渲染制作出与电影画质相当的视频。
NVIDIA BRODCAST
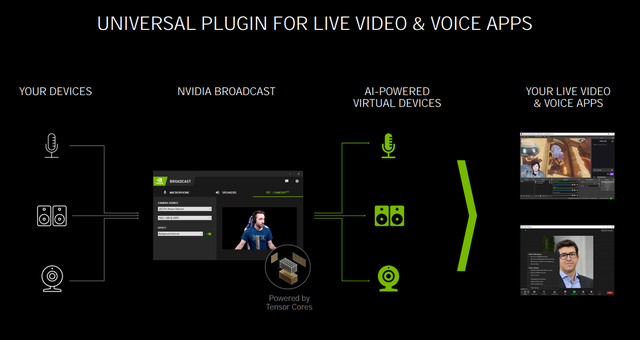
得益于RTX 30系列显卡强大的视频加速和AI用户可以轻松构建家庭工作室
NVIDIA BROADCAST该工具能为用户提供强大的直播应用解决方案,主要包括音频降噪(降低录音环境噪声)、虚拟背景(通过AI挖掘肖像,提供现场直播所需的各种虚拟背景)、摄像头自动构图(确保改变动态视频图像比例时,目标自动位于视觉中心)等实用功能。从图中可以看出,麦克风、扬声器(或耳机)、摄像头等设备连接到计算机后,通过NVIDIA BROADCAST工具可以被AI加强虚拟设备的形成,从而获得各种强大的功能。从图上可以看到,麦克风、音箱(或耳机)、摄像头等设备连接到电脑后,通过NVIDIA BROADCAST工具可以被AI加强虚拟设备的形成,从而获得各种强大的功能。
由此可见,NVIDIA Ampere架构的RTX 30显卡真的不仅仅是玩游戏,还有各种实用的黑色技术可以让你在工作中更加强大。当然,要享受如此强大的性能和功能,你必须有一个强大的RTX 30显卡,比如技嘉雪鹰GEFORCE RTX 3080 VISION OC 10G,是很多超公版RTX 3080显卡的代表作。
技嘉雪鹰GEFORCE RTX 3080 VISION OC 10G
规格参数
GPU型号:RTX 3080
核心频率:1800 MHz
CUDA数量:8704
显存规格:320 bit/10 GB GDDR6X
显存容量:24 GB
显存频率:19000 MHz
输出接口:DP 1.4a×3
HDMI 2.1×2
显卡配备风力三风扇正逆转散热系统
显卡顶部提供了支持彩色魔光效同步技术的支持LOGO灯,色调也非常适合设计师用户
背板金属装甲具有很强的设计感力和散热能力突出,提供进气格栅设计,有利于改善机箱内的散热风道
技嘉雪鹰GEFORCE RTX 3080 VISION OC 10G显卡隶属于专为设计师打造的VISION该系列采用银白搭配,散热器造型科技感十足,符合设计师的审美口味。技嘉雪鹰散热部分GEFORCE RTX 3080 VISION OC 10G配备风力3风扇散热系统,两个90mm与一个80mm风扇采用刀片风扇叶片设计,具有正逆功能,配备7根高性能纯铜导热管和巨大散热器的铜底GPU风扇支持智能启停,并在背板上设计进气格栅,这些设计有助于大大提高散热能力。此外,散热器风扇还配备了纳米石墨烯润滑油,可大大延长油封轴承风扇的使用寿命,达到滚珠轴承风扇的水平。
技嘉雪鹰GEFORCE RTX 3080 VISION OC 10G显卡还采用了独特的超耐久供电设计,配备了数字供电电路,可以有效减少MOSFET每个工作温度,每个工作温度MOSFET芯片采用固态电容器、合金电感器、低电阻晶体管等超耐久材料,提供过温保护,支持负载平衡,使用寿命长,显卡性能强,使用寿命长。在频率方面,显卡的核心频率达到1800 MHz,比公版的1710 MHz高很多,性能更好。在频率方面,显卡的核心频率达到1800 MHz,比公版的1710 MHz高很多,性能更好。
接下来,让我们来看看技嘉雪鹰GEFORCE RTX 3080 VISION OC 10G与上代旗舰相比,在实际的设计师应用中有多大的优势?
RTX 3080生产力性能测量:与上一代旗舰相比,有了很大的提升
测试平台
显卡:技嘉雪鹰GEFORCE RTX 3080 VISION OC 10G
主板:技嘉设计师Z590 VISION D
内存:技嘉 DESIGNARE DDR4 3200 32GB×2
处理器:Intel酷睿i9 10900K
硬盘:技嘉钛雕AORUS Gen4 7000s 1TB
电源:技嘉AORUS AP850GM
操作系统:Windows 10 64bit 专业版 20H2
NVIDIA STUDIO驱动461.92
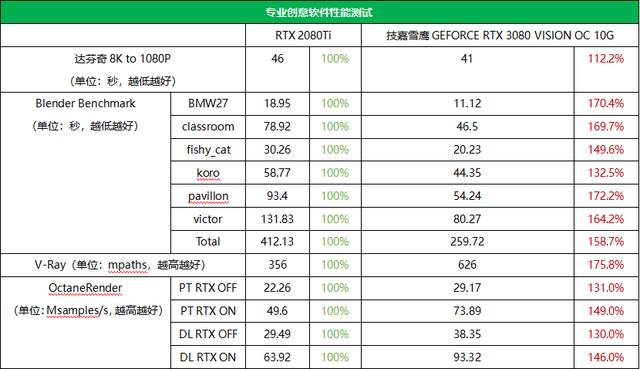
在达芬奇视频转码测试中,由于新一代的编码器和CUDA算力的大幅提升,RTX 与上一代旗舰相比,3080RTX 2080 Ti效率优势在12%左右,可以有效提高视频后处理效率。
Blender在渲染测试中,RTX 3080相对RTX 2080 Ti综合优势从32%到72%不等.7%,这很厉害。特别值得一提的是,新版本Blender使用了Optix渲染引擎,对RTX 30显卡的光跟踪加速支持也非常完善,可以更好地发挥作用RTX 第二代30显卡光追性能强,执行效率高。特别值得一提的是,新版本Blender使用了Optix渲染引擎,对RTX 30显卡的光线追踪加速支持也非常完善,能够更好地发挥RTX 第二代30显卡光追性能强,执行效率高。
V-Ray测试中,RTX 3080相对RTX 2080 Ti的优势也高 达7


